"Vanilla OpenStack" Doesn't Exist and Never Will
One of the biggest failures of OpenStack to date is expectation setting. New potential OpenStack users and customers come into OpenStack and expect to find:
- A uniform, monolithic cloud operating system (like Linux)
- Set of well-integrated and interoperable components
- Interoperability with their own vendors of choice in hardware, software, and public cloud
Unfortunately, none of this exists and probably none of it should have ever been expected since OpenStack won’t ever become a unified cloud operating system.
The problem can be summed up by a request I still see regularly from customers:
I want ‘vanilla OpenStack’
Vanilla OpenStack does not exist, never has existed, and never will exist.
Examining The Request
First of all, it’s a reasonable request. The potential new OpenStack customer is indirectly asking for those things that led them to OpenStack in the first place. The bi-annual user survey has already told us what people care about:
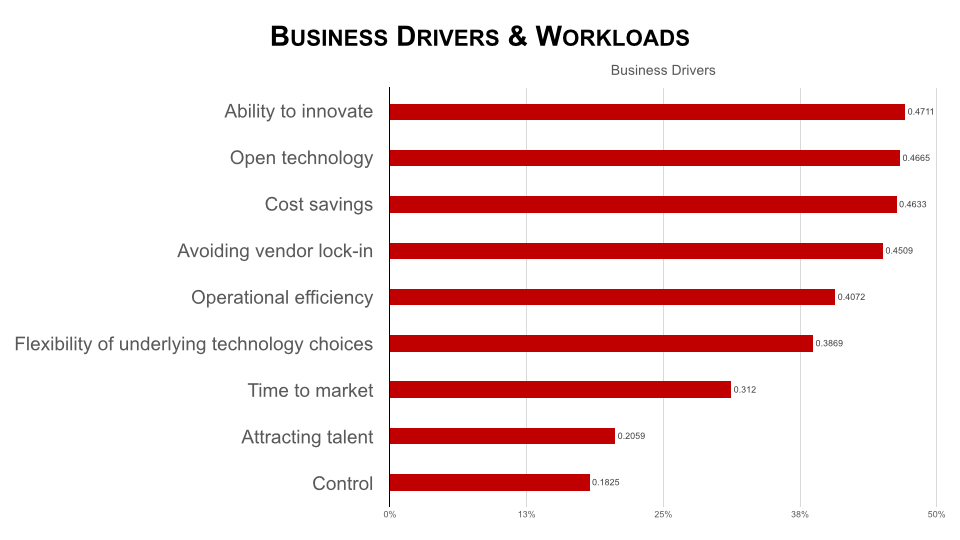
The top reasons for OpenStack boil down to:
- Help me reduce costs
- Help me reduce or eliminate vendor lock-in
Hence the desire for “vanilla” OpenStack.
But what is “vanilla”? It could be a number of things:
- Give me the “official” OpenStack release with no modifications
- Give me OpenStack with all default settings
- Give me an OpenStack that has no proprietary components
Which immediately leads into the next problem: what is “OpenStack”? Which could also be a number of things[1]:
-
Until recently, officially the principle trademark “OpenStack-powered” meant Nova + Swift only
-
The de facto “baseline” set of commonly deployed OpenStack services
1. Nova, Keystone, Glance, Cinder, Horizon, and Neutron
2. <del>There is no name or official stance on this arbitrary grouping</del>
- Use of DefCore + RefStack to test for OpenStack
UPDATE: to be more clear, the baseline set above does have a name. It is called “core” and called out in section 4.1 of the bylaws, which is below. I apologize for the confusion as “core” has been overloaded a fair bit in discussions on the board and at one point trademark rights were tied to “core”.
4.1 General Powers.
(a) The business and affairs of the Foundation shall be managed by or under the direction of a Board of Directors, who may exercise all of the powers of the Foundation except as otherwise provided by these Bylaws.
(b) The management of the technical matters relating to the OpenStack Project shall be managed by the Technical Committee. The management of the technical matters for the OpenStack Project is designed to be a technical meritocracy. The “OpenStack Project” shall consist of a “Core OpenStack Project,” library projects, gating projects and supporting projects. . The Core OpenStack Project means the software modules which are part of an integrated release and for which an OpenStack trademark may be used. The other modules which are part of the OpenStack Project, but not the Core OpenStack Project may not be identified using the OpenStack trademark except when distributed with the Core OpenStack Project. The role of the Board of Directors in the management of the OpenStack Project and the Core OpenStack Project are set forth in Section 4.13. On formation of the Foundation, the Core OpenStack Project is the Block Storage, Compute, Dashboard, Identity Service, Image Service, Networking, and Object Storage modules. The Secretary shall maintain a list of the modules in the Core OpenStack Project which shall be posted on the Foundation’s website.
So this is helpful, but still confusing. If, for example, you don’t ship Swift, which some OpenStack vendors do not, then technically you can’t call your product OpenStack-powered. HP’s public cloud and Rackspace’s public clouds, last I checked anyway, don’t use the identity service (Keystone), which also means that technically they can’t be “OpenStack-powered” either. A strict reading of this section also says that all projects that are in “integrated” status are also part of “core” and that you can’t identify “core” with an OpenStack trademark unless “core” is distributed together, which implies that if you don’t have Sahara, then you aren’t OpenStack. Which, of course makes no sense.
So my point still stands. There has been a disconnect between how OpenStack is packaged up by vendors, how the trademarks are used, and how integrated is defined and contrasted to “core”, etc.
This is why item #3 above is still in motion and is the intended replacement model for #1. You can find out more about DefCore’s work here.
Understanding The OpenStack Trademark and Its History
It’s not really a secret, but it’s deeply misunderstood: until the last few weeks, the Bylaws very specifically said that “OpenStack-powered” is Nova plus Swift. That’s it. No other projects were included in the definition. Technically, many folks who shipped an “OpenStack-powered” product without Swift were not actually legally allowed to use the trademark and brand. This was widely unenforced because the Board and Foundation knew the definitions were broken. Hence DefCore.
Also, the earliest deployments out there of OpenStack were Swift-only. Cloudscaling launched the first ever production deployment of OpenStack outside of Rackspace in January of 2011, barely 6 months after launch. At that time, Nova was not ready for prime time. So the earliest OpenStack deployments also technically violated the trademark bylaws, although since the Foundation and Bylaws had yet to be created this didn’t really matter.
My point here is that from the very beginning of OpenStack’s formation drawing a line around “OpenStack” has been difficult and still is to this day, given the way the Bylaws are written.
FYI, the new proposed Bylaws changes are explained here. You will notice that they get rid of a rigid definition of “OpenStack” in favor of putting the definition in the hands of the technical committee and board. They also disconnect the trademark from “core” itself.
Explosive Growth of Projects is Making Defining OpenStack Much Harder
There are now 20 projects in OpenStack. Removing libraries and non-shipping projects like Rally, there are still ~15 projects in “OpenStack” integrated status. And there are many more on the way. Don’t be surprised if by the end of 2016 there are as many as 30 shipping OpenStack projects in integrated status.
Many of these new projects are above the imaginary waterline many have created in their minds for OpenStack. Meaning that for many OpenStack is an IaaS-only effort. However, we can now see efforts like Zaqar, Sahara, and others are blurring the line and moving us up into PaaS land.
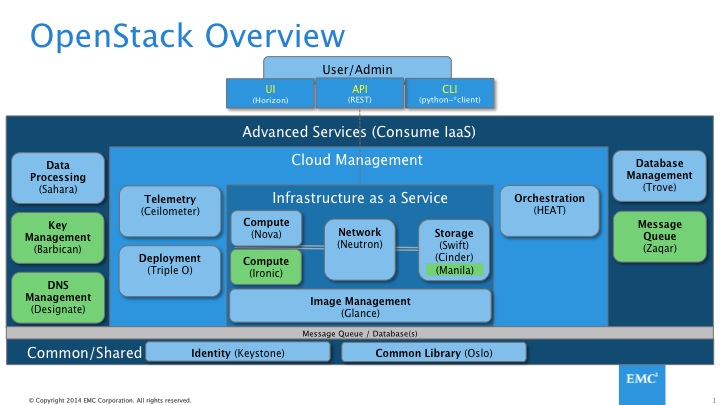
So when a customer is asking for “OpenStack”, just what are they asking for? The answer is that we don’t know and rarely do they. The lack of definition on the part of the Board, the Foundation, and the TC has made explaining this very challenging.
Vanilla-land: A Fairy-Tale in the Making
You can’t run OpenStack at scale and in production (the only measure that matters) in a “vanilla” manner. Here I am considering “vanilla” to include all three definitions above: default settings, no proprietary code, and no modifications.
UPDATE: I want to be clear that by “production” I mean large scale production deployments. Anything that requires a multi-tiered switch fabric and typically over 3-5 racks in size. Yes, people run smaller production systems; however, it’s arguable they should be all-in on public cloud instead of wasting time running infrastructure. Also, for the purposes of this article talking about 5-10 server deployments doesn’t make sense. At that size, you can obviously run “vanilla OpenStack”, but I haven’t engaged with any enterprise that operates at this scale.
The closest you can get to this is DevStack, which is not scalable nor acceptable for production.
Why?
It would really take far too long to go through all of the gory details, but I need to give you some solid examples so you can understand. Let’s do this.
General Configuration
First, there are well over 500 configuration options for OpenStack. Many options immediately take you into proprietary land. Want to use your existing hypervisor, ESX? ESX is proprietary code, creating vendor lock-in and increasing costs. Want to use your existing storage or networking vendors? Same deal.
Don’t want to reuse technology you already have? Then be prepared for a shock about what you’ll get by default from core projects.
Networking
Whether you use nova-networking or Neutron, the “default” mode is what nova-networking calls “single_host” mode. Single host mode is very simple. You attach VLANs to a single virtual machine (or a single bare metal host) which acts as the gateway and firewall for all customers and all applications. Limited scalability and performance since an x86 server will never have the performance of a switch with proprietary ASICs and firmware. Worst of all, the only real failover model here is to use a high availability active/passive model. Most people use Linux-HA, which means that on failover, you’re looking at 45-60 seconds when absolutely NO network traffic is running through your cloud. Can you imagine a system-wide networking failure of 60 seconds each time you failover the single_host server to do maintenance?
You can’t run like this in production, which means you will be using a Neutron plugin that provides control over a proprietary non-OpenStack networking solution, whether that’s bare metal switching, SDN, or something else.
Storage
Like networking, the default block storage on demand capability in Cinder is not what people expect. By default, Cinder simply assumes that each hypervisor has it’s own locally attached storage (either DAS or some kind of shared storage using Fiber Channel, etc). Calls to the Cinder API result in the hypervisor creating a new block device (disk) on its local storage. That means:
The block storage is probably not network-attachedYou can’t back the block storage up to another systemThe block device can’t be moved between VMs like AWS EBSHypervisor failure likely means loss of not only VM, but also all storage attached to it
UPDATE: Sorry folks. This was inaccurate. Cinder does use iSCSI by default.
I believe this still isn’t what customers are expecting. You would need to add HA to each cinder-volume instance combined with DRBD to do disk replication and potentially iSCSI multi-pathing for failover.
That means in order to meet the actual requirements of the customer they have to deal with the feature gaps above on their own, get an OpenStack distribution that handles the gap, or load a Cinder plugin that manages a proprietary non-OpenStack block storage solution. That could be EMC’s own ScaleIO, an open source distributed block store like Ceph, industry-standard SAN arrays like VMAX/VNX, or really anything else.
If you look at the laundry list of storage actually used in production you’ll see that over half of all deployments take this option and that the default Cinder configuration is only 23% of production deployments:
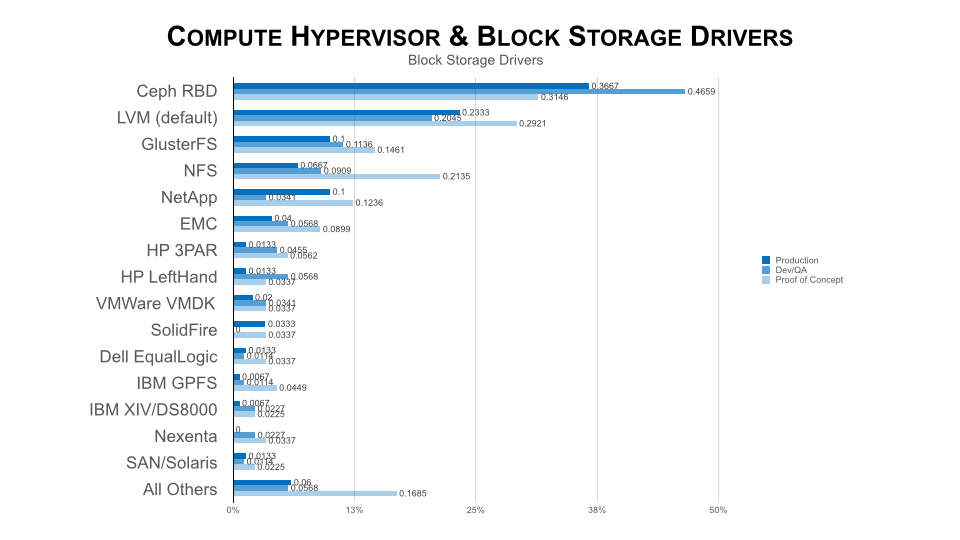
Application Management
Want your developers to create great new scalable cloud-native applications? Great, let’s do it, but it won’t be with Horizon. Horizon is a very basic dashboard and even with Heat, there are major gaps if you want to help your developers succeed. You’ll need Scalr or Rightscale as cloud application management frameworks (especially if you are going multi-cloud or hybrid cloud with the major public clouds) or you’ll need a PaaS like CloudFoundry that does the heavy lifting for you.
You Can Reduce Vendor Lock-in, But … You Can’t Eliminate It
Are you trying to eliminate vendor lock-in? Power to you. That’s the right move. Just don’t expect to succeed. You can reduce but not eliminate vendor lock-in. It’s better to demand that your vendors provide open source solutions, which don’t necessarily eliminate lock-in, but does reduce it.
Why isn’t it possible? Well, network switches, for example, are deeply proprietary. Even if you went with something like Cumulus Linux on ODM switches from Taiwan, you will still run proprietary firmware and use a proprietary closed-source ASIC from someone like Marvell or Broadcom. Not even Google gets around this.
Firmware and BIOS on standard x86 servers is all deeply proprietary, licensed strictly, and this won’t change any time soon. Not even the Open Compute Project (OCP) can get entirely around this.
The Notion of Vanilla OpenStack is Dangerous
This idea that there is a generic “no lock-in” OpenStack is one of the most dangerous ideas in OpenStack-land and needs to be quashed ruthlessly. Yes, you should absolutely push to have as much open source in your OpenStack deployment as possible, but since 100% isn’t possible, what you should be evaluating is what combination of open source and proprietary get you to the place where you can solve the business problem you are trying to conquer.
Excessive navel-gazing and trying to completely eliminate proprietary components is doomed to failure, even if you have the world’s most badass infrastructure operations and development team.
If Google can’t do it, then you can’t either. Period.
The Process for Evaluating Production OpenStack
Here’s the right process for evaluating OpenStack:
-
Select the person in your organization to spearhead this work
-
Make him/her read this blog posting
-
The leader should immediately download and play with DevStack
-
The leader should create a team to build a very simple POC (5 servers or less)
-
Understand how the plugins and optional components work
-
Commission a larger pilot (at least 20-40 servers) with a trusted partner or set of trusted partners who have various options for “more generic” and “more proprietary” OpenStack
-
Kick the crap out of this pilot; make sure you come with an exhaustive testing game plan
1. VM launch times
2. Block storage and networking performance
3. etc…
-
Gather business requirements from the internal developers who will use the system
-
Figure out the gap between “more generic” and “more proprietary” and your business requirements
-
Dial into the right level of “lock-in” that you are comfortable with from a strategic point of view that meets the business requirements
-
If at all possible (it probably won’t be, but try anyway), get OpenStack from a vendor who can be a “single throat to choke”
Summarizing
I am trying to put a pragmatic face on what is a very challenging problem: how do you get to the next generation of datacenter? We all believe OpenStack is the cornerstone of such an effort. Unfortunately, OpenStack itself is not a single monolithic turn key system. It’s a set of interrelated but not always dependent projects. A set of projects that is increasing rapidly and your own business probably needs only a subset of all the projects, at least initially.
That means being realistic about what can be accomplished and what is a pipe dream. Follow these guidelines and you’ll get there. But whatever you do, don’t ask for “vanilla OpenStack”. It doesn’t exist and never will.
[1] Mark Collier pointed out some inaccuracies and I have adjusted this bullet list to reflect the situation as correctly as possible.