The Rancher's Dilemma: Reconciling Pets & Cattle
When I first started promulgating the pets vs. cattle meme, it really helped me get through roadblocks of confusion. Many in IT couldn’t tell the difference between the old way and the new way. Explaining “cloud native” could take a long time, but this meme gave me a way to explain in 30-seconds flat. It’s gone and morphed in many ways (chickens replacing cattle, addition of ants, etc.). My favorite by far is when a bunch of CIOs in a Gartner Research Board meeting added “children” (mainframes), unwittingly delineating the three platforms or three de facto generations of IT.[1]
However, I knew even when using this meme that a day would come its relevance would dim. We aren’t there yet, but I see the writing on the wall, and I want to talk about this today.
Before I do though, let me say that pets vs cattle is still alive and well. As I talk to customers worldwide, I see recurring themes where folks who go “bi-modal” per Gartner are successful, while those who attempt to “cross the streams” and run legacy and cloud native on the same systems inevitably fail. In fact, this is one of my top 6 causes for failed deployments in OpenStack land:

Still time marches on and I want to share why it is ultimately possible to cross the streams. Let’s also discuss what remains to get to a place where we can all become ranchers, incorporating pets, cattle, and perhaps children onto a single farm/ranch/infrastructure that can accommodate a variety of generational IT workloads.
Background: The Three Platforms
In order to understand the rest of this blog posting, you need to wrap your head around the generational shift in IT patterns that IDC outlined and called the First, Second, and Third Platforms:
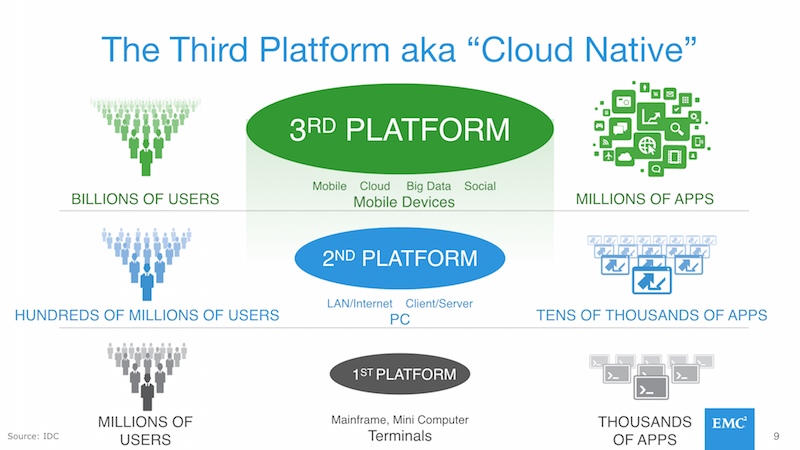
At root is that each succeeding generation makes fundamentally different tradeoffs in order to meet challenges around scale, adoption, and customer engagement models. I think the slide is relatively self-explanatory so I won’t go into detail here. The thing to keep in mind is that each era is effectively different in how technology, people, and processes are deployed.
Here’s a diagram that covers enough of a subset of characteristics as to make it clear what I mean:
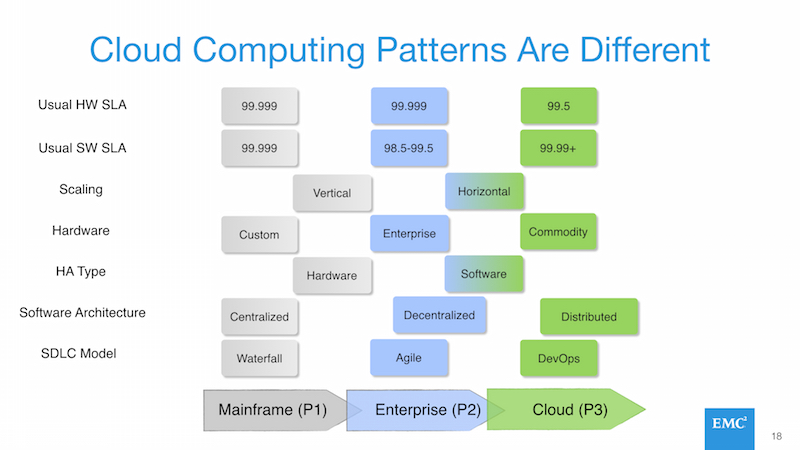
Differing Generational IT Workload Requirements
Although there are many differences between the second and third platforms, I believe the pets vs cattle meme has been as successful as it has because it highlights the biggest difference: servers as a disposable, commodity item. No identity and low or no cost. Treating servers like electrical amps, data packets, cellular minutes, oil, gas, or anything else that is a true commodity.
This is only possible because the responsibility for resiliency and data redundancy moves from the server or infrastructure layer into the application layer, making the overall importance of any individual server or infrastructure component irrelevant.

Applications on the left hand side of this equation must have “gold plated hardware” deployed in order to deal with their own inability to handle system failures. Applications on the right hand side are the opposite.
This is why attempts to build a system that works for both usually fail.
Gold plating the hardware and infrastructure stack drives up cost, making cloud-native or third platform applications unreasonably expensive to run and maintain. [2]
Putting legacy applications on more modern and cheaper infrastructure is inexpensive, yet those applications can’t route around failures and are likely to experience greater downtime.
Is it possible to have a modern, inexpensive, software-centric infrastructure system that has enough elements of infrastructure resiliency to allow legacy apps to run?
Certainly! Although not all of the elements are there today. Some are though and the quality of those components has increased dramatically in the past year or so.
Storage Tools & Technology for the Modern Cloud Rancher
A key tool for those trying to enable “cloud ranchers” is “live migration”. The ability to move a virtual machine or possibly container between hosts without impacting the running workload. This requires a shared storage system that was traditionally provided by a complex and expensive fiber channel SAN (FC-SAN). More modern approaches like ScaleIO, VSAN, and Ceph provide so-called “server SANs” that replace FC-SANs with a software-centric scale-out model running on top of generic commodity servers.
Most server SAN products provide rough feature parity with the classic FC-SAN model, but have shortcomings in a variety of places. One example is the need for esoteric capabilities like the “quorum” or “voting” disks for Oracle RAC that require multi-master writes (multiple servers can write to the disk simultaneously). Another example is the need for synchronous SRDF to commit simultaneous writes to two separate storage servers separated by hundreds of miles and connected by dark fiber.
Some of these technology gaps are able to be overcome and some are not. Certain server SANs, like ScaleIO, can support the quorum disk requirement for Oracle RAC. Others, like SRDF, simply can’t ever be built in the scale-out model (unless you know how to scale out dark fiber drops dynamically to your growing cluster of commodity servers - if so, let me know… we can make some serious scratch!).
Today’s OpenStack deployments can support live migration if they use ScaleIO or Ceph as the underlying storage substrate. More importantly, these software-centric storage systems can run on top of generic commodity storage and drive the relative cost of storage towards zero. In effect, providing different infrastructure value propositions for legacy or cloud-native applications. Some, like ScaleIO, even have the performance of FC-SANs and can provide equivalent performance to modern all flash arrays.
We Aren’t There Yet
I’ve only touched on storage here and very lightly on compute. There are a number of other gaps that need to be filled before you can succeed at running pets and cattle applications on the same system. For example, the scheduling system(s) in OpenStack aren’t where they can replicate VMware DRS and HA. Even when that happens, you would need to enable the capability selectively per application, since providing DRS and HA to cattle applications is a bad idea. [3]
The point is that we’re starting to see the window open on delivering a unified infrastructure system that enables us to support pets and cattle simultaneously.
Getting a Taste of the Future
If you are in Austin, TX next week for the OpenStack Summit, myself and some EMC colleagues are going to demonstrate the live migration of a pet-based workload (Oracle) running on top of OpenStack with ScaleIO as an underlying substrate. We will show live migrating a massive Oracle database server (64GB RAM) with little or no impact to overall storage system throughput (~10% or less) running on a hyperconverged OpenStack cluster (migration network and storage network are shared).
The point of this will be to show how at least the storage system components necessary to support legacy workloads in modern cattle clouds is mature and ready to go.
Here are the details if you wish to attend:
| Presentation Title | Using ScaleIO in an OpenStack Environment |
| Date & Time | Monday, April 25, 3:40pm-4:20pm |
| Location | Austin Convention Center - Level 4 - MR 18 A/B |
Wrapping Up
It’s just a matter of time before pets and cattle are reconciled by cloud ranchers. In the meantime, check yourself before you wreck yourself. Trying to cross the streams is still a top cause for failures. There are no panaceas in IT. I guarantee you won’t see scale-out, high performance, SRDF any time soon. You are always making tradeoffs. It just so happens that sometimes we can make tradeoffs that accommodate more than one master.
[1] More about this soon.
[2] Increasing the cost of the infrastructure and apps also impacts speed of delivery as the more expensive an initiative is, the more likely those in charge are to attempt to de-risk it, adding more costs, slowing things down, and generally being far more conservative than is probably necessary.
[3] You can’t have the intelligence in the system at the app and infrastructure layer simultaneously. If you did, you would create race conditions and potentially other “tug of war” type problems as both the app and infrastructure tried to manage server availability simultaneously.