The 6 Requirements of Enterprise-grade OpenStack, Part 3
In part 1 and part 2 of this series I introduced the core ideas around defining the requirements and then discussed the first four. Today we’ll discuss the final two requirements and tie it all together.
Onwards and upwards!
Requirement #5 – Scalable, Elastic, and Performant
Enterprise-grade has to mean something. In the past, enterprise-grade related to a certain quality of a system that made it highly reliable, scalable, and performant. More and more, enterprise-grade is beginning to mean “cloud-grade” or “web scale.” What I mean by that is that as the move to next generation applications happens and enterprises adopt a new IT model, we will see major changes in the requirements for delivering a high quality system.
The example I love to use is Hadoop. Hadoop comes with a reference architecture that says: use commodity servers, commodity disk drives, and NO RAID. When is the last time you saw an enterprise infrastructure solution with no data protection at the hardware layer? Of course, it doesn’t make sense to run Hadoop on high end blades attached to a fiber channel SAN, although I have seen it. Even Microsoft Exchange has begun recommending a move towards JBODs from RAID and depending on the application software layer to route around failure.
Let’s talk about these three requirements for enterprise-grade OpenStack.
Scalability & Performance
Scalability is the property of a system to continue to work as it increases in size and workload demands. Performance is the measurement of the throughput of an individual resource of the system rather than the system itself. Perhaps Werner Vogels, CTO of Amazon, said it best:
A service is said to be scalable if when we increase the resources in a system, it results in increased performance in a manner proportional to resources added.
In many ways, OpenStack itself is a highly scalable system. It was designed around a loosely-coupled, message passing architecture – something tried and true for mid to large scale, while also able to scale down to much smaller size deployments. The problem, unfortunately, lies in what design decisions you made when configuring and deploying OpenStack. Some of its default configurations and many of the vendor plugins and solutions have not been designed with scale in mind.[1] When you read the previous installment, you understood that having a reference architecture is critical to delivering hybrid cloud. Make certain you pick an enterprise-grade product with a reference architecture that cares about scale and performance while using well-vetted components and configuration choices.
A complete examination of the scale and performance issues that might arise with OpenStack is beyond the scope of this series; however, let’s tackle the number one issue that most people run into: network performance and scalability.
OpenStack Default Networking is a Bust
OpenStack Compute (Nova) has three built-in default networking models: flat, single_host, and multi_host. All three of these networking models are completely unacceptable for most enterprises. In addition to these default networking models, you have the option of deploying OpenStack Networking (Neutron), which has a highly pluggable architecture that supports a number of different vendor plugins both to manage physical devices and also network virtualization systems (so called Software-defined Networking or SDN).
A very brief explanation of the default networking models shortcomings is in order. I will keep it very simple, but am happy to follow up later with more details. The flat and multi_host networking model requires a single shared VLAN for all elastic (floating) IP addresses. This requires running spanning tree protocol (STP) across your switch fabric, a notoriously dangerous approach if you want high network uptime. I’ve asked the question at multiple conferences to a full room: “How many of you think STP is evil?” and have had nearly everyone in the room raise their hand.
Perhaps more importantly, both flat and multi_host networking models require you to route your public IP addresses from your network edge down to the hypervisor nodes. This is really not an acceptable approach in any modern enterprise. Here’s a diagram showing multi_host mode:
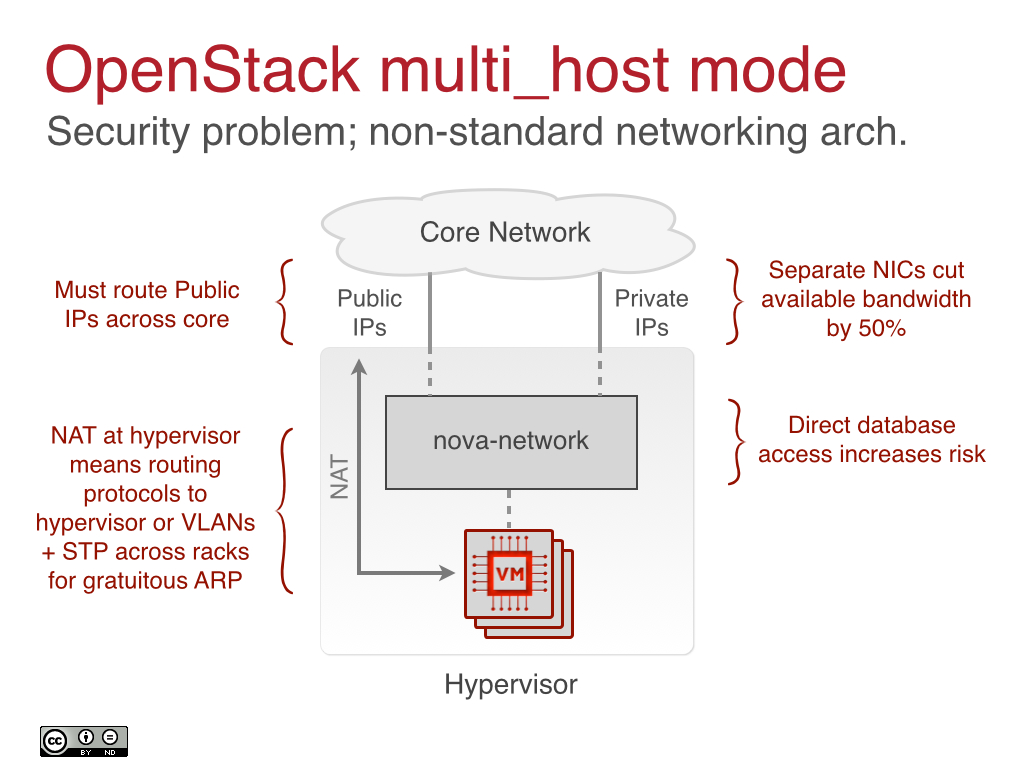
It’s probably also worth noting that if you want multi_host mode, you need to be able to load code on your hypervisor. That means if you like ESX or Hyper-V you are probably out of luck.
By contrast, single_host mode suffers from the singular sin of trying to make a single x86 server the core networking hub through which all traffic between VLANs and the Internet runs.[2] Basically, take your high performance switch fabric and throw it in the trash because your maximum bandwidth is whatever a Linux server can push. Again, this is not an acceptable or even credible approach to networking. To be fair though, OpenStack competitors also took a similar approach to this. Here’s a diagram on single_host mode:
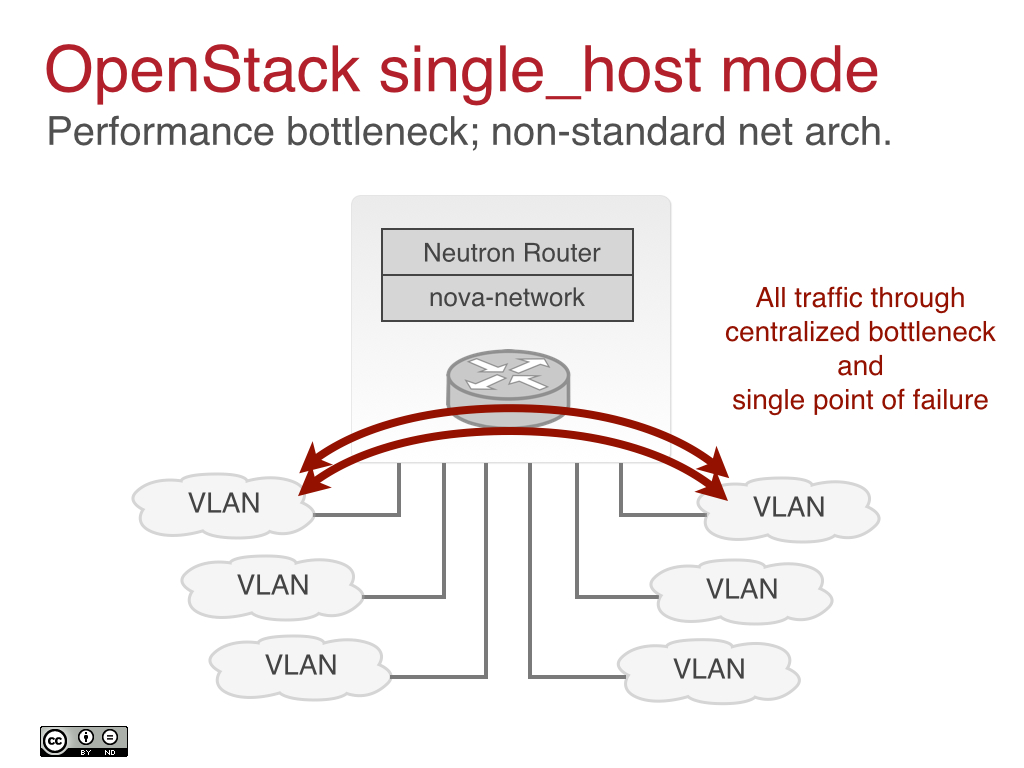
All of these approaches have fundamental scalability and performance issues. Which brings us to OpenStack Neutron.
Depending on OpenStack Neutron NOT for the Faint of Heart
As of September 2013, it seems like Neutron still had significant issues as seen in this critical posting from Scott Devoid of Argonne National Labs (ANL) to the OpenStack operators mailing list. As of this writing, OpenStack Neutron supports single_host and flat modes, but not multi_host. Apparently, we may see a replacement for multi_host in the Juno timeframe, although this capability has been missing for a while now.
That being said, Neutron has made a lot of progress and to be honest, many of the issues folks have reported are more likely to stem from poorly written and adapted plugins. What this means is that in order to deliver success with OpenStack Neutron you need a version of Neutron plus accompanying plugins that have been designed for scale and performance.[3] Plus, your cloud operating system vendor should have some proven deployments at scale and have really beaten the crap out of the networking using exhaustive testing frameworks.
I could say much more about the performance and scalability of an enterprise-grade, OpenStack-powered product; however, it should give you a starting point in pinning down your vendors to make sure they have addressed these and related issues.
Most important: regardless of your OpenStack vendor they must be able to provide a detailed, multi-rack reference network architecture.
Without a reference network architecture, your ability to scale past a single rack is purely based on hand-waving and assurances from your vendor that may or may not have any validity.
Elasticity
Infrastructure can’t ever be truly elastic, but its properties can enable elastic applications running on top of it. An elastic cloud is one that has been designed such that individual cost of resources such as VMs, block storage, and objects is as inexpensive as possible. This is directly related to Jevon’s Paradox, which states that as a technology progresses, the increase in efficiency leads towards an increase in the rate of consumption of that technology:
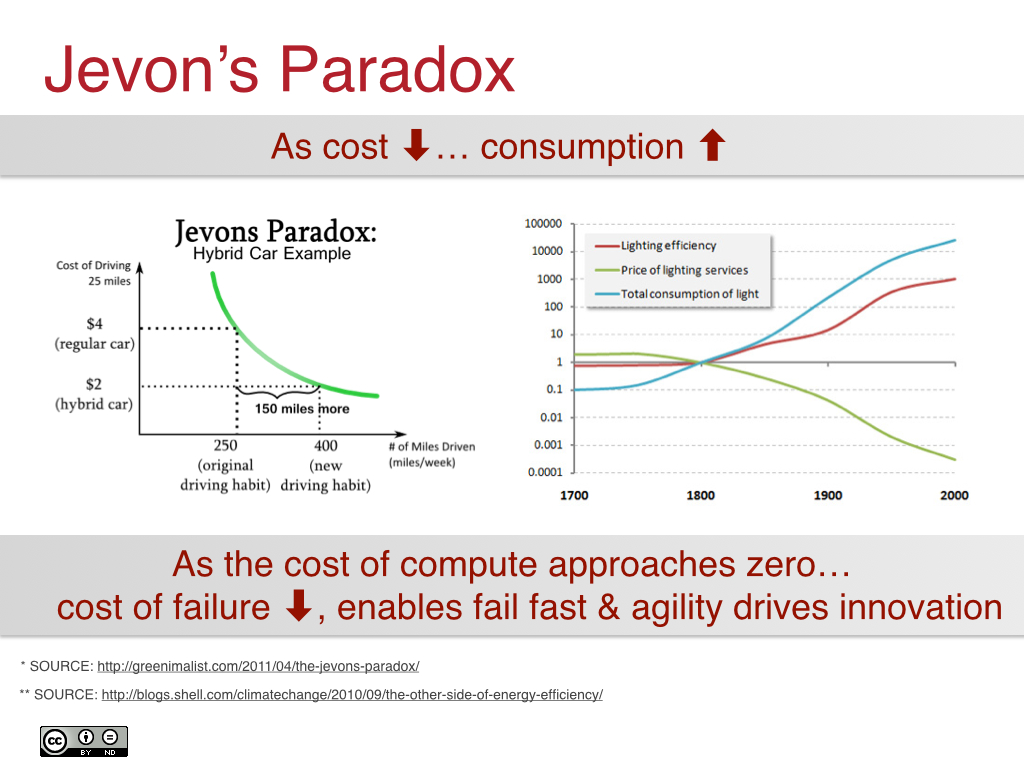
Simply put, as the relative cost of components in the system reduces, applications can not only consume more, which enables routing around failures, but also consume more for the purposes of scaling application needs up and down based on demand. In essence, you can make the pool larger and buy more capacity if the individual components and resources are as cheap as possible.
Major elastic public clouds like Google, Amazon, and Microsoft are providing these kinds of properties, and it’s what you need to provide inside your four walls to enable hybridization.
Enterprise-grade OpenStack will help lead you into the future by providing scalability and performance while supporting elastic applications. Beware the OpenStack-powered cloud operating system that wants you to use a fiber channel SAN and blade servers. Those days have passed, as we can see with Hadoop.
Requirement #6 – Cloud Support, Training & Services Model for Global Enablement
Chances are you are a global organization and are planning to deliver 24x7x365 next generation, cloud native applications on top of your private, public, and hybrid clouds. You want partners who can support you globally, who have international experience, and most of all who are comfortable with supporting 24x7x365 environments.
Train Your IT Administrators to be the New Cloud Administrators
IT administrators are in the process of transitioning into cloud administrators. This evolution will be a deep and lasting change inside the enterprise. Entirely new sets of skills need to be developed and other skills refreshed and realigned to the new cloud era. When evaluating your enterprise-grade OpenStack partner, you should be looking for one with significant capabilities in training, both on generic OpenStack and on their specific cloud operating system product. Most importantly, when evaluating a partner who can help you upgrade your team’s cloud skills, make certain they aren’t just going to show you how to develop on OpenStack or install OpenStack.
What you really need is operator-centric training that focuses on:
-
Typical OpenStack architectures and specific product architectures
-
Pros and cons of various architecture and plugin/driver choices
-
Scalability, interoperability and performance issues and options
-
Troubleshooting common “full stack” problems
-
Introduction to how your developers will use your cloud
-
Understanding the cloud-native application model
Cloud Support Model
No matter how good your IT team is, you will need a trusted support team to back you up — a team that can support your entire system end-to-end. Make certain you ask your Enterprise-grade OpenStack-powered cloud operating system vendor if their support team has supported high transaction 24x7 environments before. Be certain that they have so-called “full stack” support capabilities. Can they troubleshoot the Linux kernel, your hypervisor of choice, networking architecture and performance issues, and do they understand storage at a deep level? Clouds are integrated systems and compute, storage, and networking all touch each other in fundamental ways. Your vendor needs to know a lot more than how to configure or develop for OpenStack. They need to be cloud experts at all levels of the stack. Demand it.
Global Service Delivery
Delivering a cloud internationally is no small feat, whether large or small.[4] It requires more than just reach. It requires cultural sensitivity and the ability to understand the unique requirements that arise in particular geographies. For example, did you know that while most data centers are more concerned over power than space, in Japan it’s still usually just the opposite. Space winds up being one of the single largest premiums. This space requirement is unique to their particular environment.
Your cloud operating system vendor should have a track record of successful international delivery and a partner network that can assist in a particular location.
Conclusion
OpenStack is an amazing, scalable foundation for building a next generation elastic cloud, but it’s not perfect. None of the open source solutions it competes with are perfect either. Instead, each of these tools is really a cloud operating system “kernel” that can be used to deliver a more complete, vetted, Enterprise-grade cloud operating system (cloudOS). You will need an experienced enterprise vendor to deliver your cloudOS of choice and whether it’s OpenStack or another similar project I hope you will keep these requirements in mind.
I hope you enjoyed this whirlwind tour through the 6 Requirements of Enterprise-grade OpenStack. As a reminder, we covered these SIX requirements:
-
99.999% Uptime APIs & Scalable Control Plane
-
Robust Management & Security Models
-
Open Architecture
-
Hybrid Cloud Interoperability
-
Scalable & Elastic Architecture
-
Global Support & Services
As you are out there evaluating the right vendor to help with your OpenStack adoption process and the move towards hybrid cloud, make certain you find out how much, if any of these requirements they can meet.
For some related white papers, check out:
[1] It’s also fair to say that some times people are using the messaging systems in an inappropriate manner. Some times, plain old UDP is still best for fire and forget high throughput systems, like logs.
[2] Before you cry foul, others such as Eucalyptus also went down this unfortunate path. I believe Eucalyptus 4.0 finally fixes this. It’s a common mistake for people without networking experience to go down this path.
[3] So far the only one we have tested extensively is OpenContrail, which shows great promise, but we have to get running in some larger deployments before we declare victory.
[4] We know. Building the KT uCloud in 2010 and 2011 was a huge task for an early stage startup.