Project CoprHD's Architecture
Unless you had your head in the sand, you probably saw my blog post talking about Project CoprHD (“copperhead”), EMC’s first open source product. Exciting times are ahead when one of the world’s largest enterprise vendors embraces open source in a big way. Does it get any bigger than picking your flagship software-defined storage (SDS) controller and open sourcing it? But there is a bigger story here. The story of CoprHD itself and specifically its architecture. CoprHD is a modern application architecture from the so-called “third platform” or “cloud native” school of thought. You probably didn’t know this and you may even be a little curious what goes into CoprHD.
So I thought I would give you a basic overview on CoprHD and then a short comparison to OpenStack Cinder, which is the closest analog to CoprHD out there today. CoprHD is meant to work with Cinder, but in the same way that OpenDaylight plays nice with OpenStack Neutron (both “software-defined networking controllers”). There is overlap, but the current OpenStack cultural environment doesn’t really allow swapping out individual components without a lot of blowback, so most software-defined-* controllers simply integrate to existing OpenStack projects to reduce friction and encourage adoption. CoprHD is no different.
Let’s get to it.
Introduction to Software-Defined-* Controllers
SDS or SDN can seem a little confusing at first, but for me it’s easy. There are two parts, the control plane and the data plane:
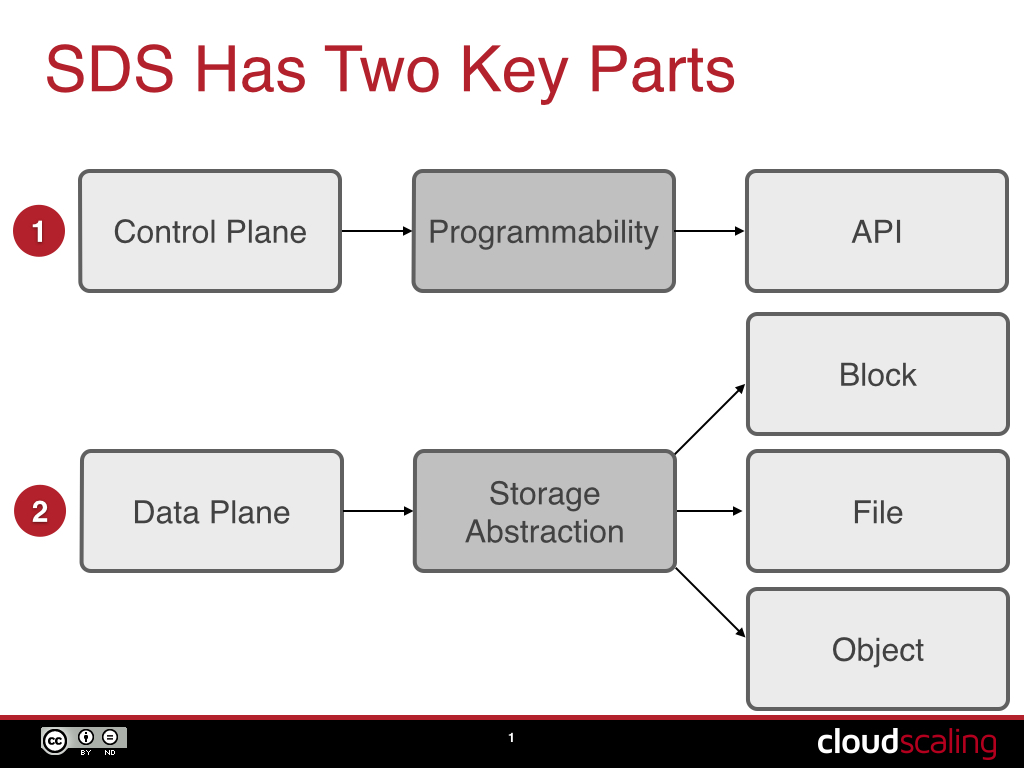
These two parts represent the two fundamental components of anything that is “software-defined”, which is programmability (“software-defined”) and the abstracted resources driven through the API (“virtualization” is the commonly used term, but I will reserve that for compute only).
Frequently, the control plane and data plane are separated, although there is a movement around “hyperconverged” to collapse them, which I have an issue with. When talking about SDS or SDN, the separated control plane is referred to as the “controller”. So you will see folks talk about “SDN controllers” in the networking space and they are referring to things like OpenStack Neutron, OpenDayLight, the OpenContrail Controller, and the VMware NSX Controller.
As you might infer, given the name “software-defined”, the control plane is one of the more critical components in an SDS architecture. To date there has been little or no SDS controller in the marketplace other than OpenStack Cinder and ViPR Controller. So the open sourcing of ViPR into Project CoprHD is extremely important.
An SDS controller is your primary tool for managing storage systems, be they legacy storage arrays or modern scale-out software-only storage solutions; and regardless of whether they are block, file, or object. SDS controllers should:
-
reduce complexity
-
decrease provisioning times
-
provide greater visibility and transparency into the managed storage systems
-
reduce cost of storage operations and management
-
be architecturally scalable and extensible
This last item is what I really want to talk about today, because while CoprHD gives you #1-4, #5 is where it really shines. #5 is also a large part of why we chose to open source CoprHD.
CoprHD’s Cloud Native Architecture
Now that CoprHD is out you can check out the code yourself. We’re still in the process of getting all of the pieces together to take pull requests and move our documentation into the public. Something like this isn’t simple, but there is some initial documentation that I want to walk you through.
CoprHD’s design principles are:
-
CoprHD must be scalable and highly available from the very beginning
- Scalability should not be an add-on feature
-
It must use Java on Linux [1]
- A good server platform with good support for concurrency and scalability
-
Must use solid and popular open source components extensively
- Allowing for focus on the real issues without reinventing the wheel
-
Must avoid redundant technologies as much as possible
- Adding new technology often adds new problems
-
The system console must be for troubleshooting only
- All operations must have corresponding REST calls
That seems like a solid set of initial design goals.
Let’s take a look at a typical CoprHD deployment:

Here we can see where CoprHD sits relative to the other components in a modern cloud or “software-defined datacenter” (SDDC).
In the box labeled CoprHD above, which represents a CoprHD Cluster (3 or 5 identical servers) are:
-
Reverse web proxy & load balancer (nginx)
-
Robust GUI framework (play framework)
-
REST API and GUI (EMC-written Java code)
-
SDS controller business logic (EMC-written Java code)
-
Distributed data store (Cassandra)
-
Distributed coordinator (Zookeeper)
Here is a more precise diagram showing more of the individual services each running on identical nodes in a 3-node cluster.
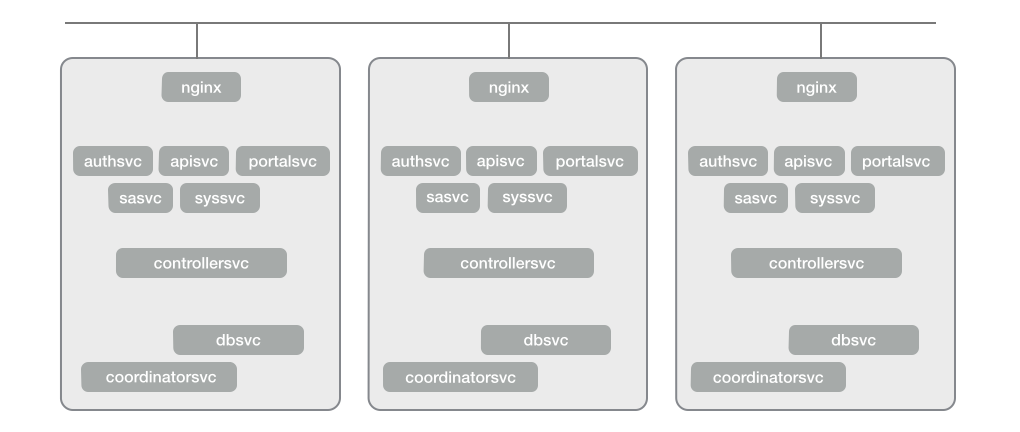
You can figure out the mapping of the components in the list above I gave you to the boxes above, I’m certain. Or refer to the formal documentation for more details.
Each CoprHD server is identical, using Cassandra to replicate data between nodes, Zookeeper to coordinate services across nodes, nginx as proxy and load-balancer, and VRRP for service failover.
I love this approach because it uses a bunch of well-baked technologies and doesn’t get overly experimental. VRRP and Zookeeper’s quorum are tried and true. Cassandra powers some of the world’s largest cloud services. Most importantly, this is clearly a “cloud native” pattern, using scale out techniques and distributed software. There are no single points of failure and you can run up to 5 servers according to the documentation, although I don’t see any inherent flaws here that would stop you from running 7, 9, 11, or more (always an odd number to make certain the Zookeeper quorum works).
CoprHD’s Pluggable Architecture
The documentation unfortunately isn’t up yet, but CoprHD supports managing a wide variety of traditional storage arrays and cloud storage software, including EMC hardware systems (VNX, VMAX, etc), EMC software systems (ScaleIO), NetApp, and Hitachi Data Systems. This means the CoprHD system and the controllersvc specifically have been designed to be extensible and have a pluggable architecture.
In addition, by integrating to OpenStack Cinder, CoprHD can support the management of additional hardware vendors. The major downside here, of course, is that it’s difficult to deploy Cinder by itself. You’ll need a fair bit of the rest of OpenStack in order to get it up and running.
CoprHD’s Scalable Control Interfaces: REST API & Non-Blocking Async GUI
One of the signatures of the third platform is that the control systems need to scale well. This is because systems are highly automated and the new API-centric model means that there will be large numbers of API calls. Related, mobile applications and interfaces take advantage of technologies such as WebSockets, to allow a more interactive GUI than before. Another interesting challenge is that for both the API and GUI, some interactions are inherently synchronous (you take an action and see an immediate result) and some are asynchronous (take an action and wait for a result to be sent back [push] or query regularly for a response [poll]).
CoprHD uses a standard shared nothing architecture and the only state resides in the Cassandra cluster. This means that the REST API can be run on all active nodes and effectively scale to the size of the number of nodes. The GUI was designed on top of the Play Framework, which is designed as a distributed non-blocking asynchronous GUI that is mobile friendly. This is the same GUI framework that powers massive websites like LinkedIn.
Combined, CoprHD’s built-in API and GUI are designed for true scale.
Cassandra as Distributed Data Store
Cassandra is covered elsewhere, but I always like to point to this slide I used to describe Netflix’s testing of it. What you see here is near perfect linear scale moving from 50 to 300 servers. And I think that says pretty much all you need to know about Cassandra scalability.

##
Comparing CoprHD vs. ScaleIO, Ceph, Cinder, and Manila
The last thing I think we need to do is a quick comparison against some of what are considered CoprHD’s contemporaries. I don’t really see them that way, but folks will draw parallels and I’d like to tackle those head on. Right off the bat we should be clear: CoprHD is designed to be an independent SDS controller, whereas the rest of these tools are not. CoprHD is also designed to be vendor neutral and designed for file/object/block.
So here’s a quick comparison chart to make things clear. This comparison is purely about the SDS controller aspects of these technologies, not about storage capabilities themselves.
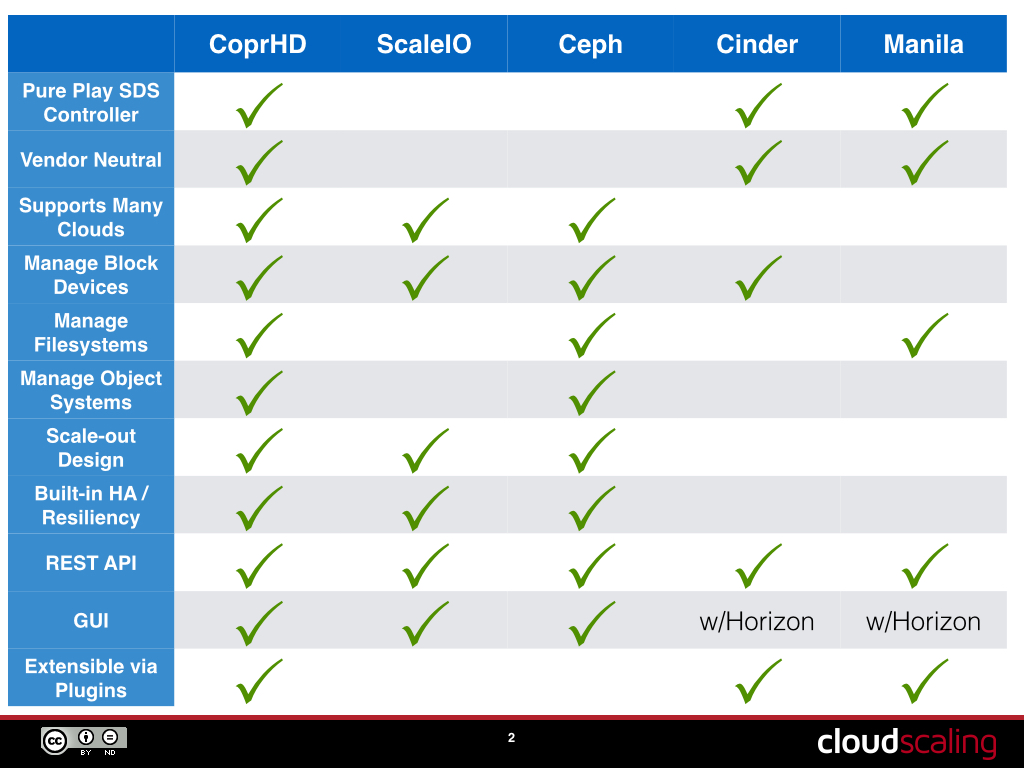
I am not going to spend a lot of time on this chart. Some may argue about its contents, but probably any such arguments will come down to semantics. The takeaway here is that CoprHD is the only true scale-out pure-play SDS controller out there that is open source, vendor neutral, and designed for extensibility.
Summing Up CoprHD
CoprHD is written for the third platform and designed for horizontal scalability. It can act as a bridge to manage both legacy “second platform” storage systems and more modern “third platform” storage systems. It is open source and is building a community of like-minded individuals. CoprHD delivers on the criteria required to be a successful SDS controller and has an architecture that is scalable and future-proofed. It should be at the center of any SDS strategy you are designing for your private or public cloud.
[1] Some folks are allergic to Java. I’m not a fan, but I’ve never figured out why they take issue other than it’s verbosity. C++ isn’t exactly terse. For those critical of Java’s place in the “third platform”, you should be aware that large chunks of Amazon Web Services (AWS) are written in Java. It’s still one of the most robust language virtual machines out there and that’s why next generation languages like Scala and Clojure run on top of it, eh?