Google is Amazon's Only Real Competition
Recently, Barb Darrow wrote a note to Google Compute Platform, suggesting “8 Things it Could do to Freak Amazon out.” As long term readers know, I called out Google’s entry into the public Infrastructure-as-a-Service (IaaS) a while ago. My extensive experience at GoGrid and in the service provider and hosting business, provides me with a deep understanding of the public cloud market’s underlying business models and technologies. Cloudscaling also created the Google Compute Engine (GCE) APIs for OpenStack, which were finally submitted and made available via StackForge just today (more on that later).
Barb’s recommendations to Google were a good start, but I would like to expand a bit on her original article. Here are my thoughts.
8 Things GCE Could do to Freak out Amazon
#0 - sub-hour payment increments
This is not in the official list as it seems to be taken for granted that GCE already does this (they do) and that AWS should be concerned (they shouldn’t). While sub-hour payments sound good as it provides greater granularity in billing, it’s doubtful that most people will shave off any significant dollars. The main reason is that an hour of granularity is reasonably good and that most workloads expand during the day and contract at night following the general pattern of daily Internet traffic. The secondary reason is that when you combine server failure detection times with new VM spin up times and initial provisioning times, you are going to be well into a full hour. We simply aren’t at a point where the majority of apps spin up VM capacity rapidly (<1 minute) and spin it back down quickly. Elasticity is measured in hours, not minutes right now. That will change over time, but sub-hour payment increments are a premature optimization and marketing differentiation more than a reality for most customers right now.
#1 - Provide Reserved Instances
Makes sense. Couldn’t agree more. I’m sure they are hard at work thinking about it, but this is not a very big challenge so I’m sure Google will get to it when it makes sense to them and as Barb says it’s likely GCE is doing this on a case by case basis already.
#2 - More Managed Service-y Services
Google was churning out developer friendly services before Amazon even launched EC2 and it’s been cranking them out just as consistently. If you actually look at the Google dashboard you will be stunned at their ecosystem of services. It already eclipses AWS. I think it’s a mistake to look at Google as having to “catch up” to Amazon. What really happened is that Google started at the application layer and has been working down towards infrastructure, while Amazon started at the infrastructure layer and has been working up towards applications. Neither is really “ahead” of the other in the broader sense, although if you pick specific services, clearly their respective “leads” are relative to where a given services is in their “stack”. If it’s closer to the application layer, Google’s ahead, closer to infrastructure, Amazon is ahead.
#3 & #4 - Parlay Search / Get Louder
Not much to say here. These seem self-evident and I’m sure we’ll see more from Google given how they have been accelerating recently.
#5 - Offer More and Different Types of Instances
Makes sense. Customers want choice and variety. I am certain we will see choice increase over time. I will respectfully disagree with the smart and talented Sebastian Stadil however. It’s actually a mistake to provide live instance resizing. This is one of those kinds of suggestions that makes a ton of sense from the cloud end-user perspective, but actually has a negative impact for the public cloud provider. Live instance resizing isn’t strictly technically hard. Guest OSes support “hot plug” of RAM, CPUs, and other virtual hardware components and most hypervisors also support this. The problem however is that if you allow arbitrary instance resizing it’s very difficult or impossible to provide QoS and resource SLAs on a per instance basis. You also stand a very good chance of blowing up your business model by not having an even “bin packing” of instances on hardware. Most of these clouds need to run at around 80% sold capacity for the business model to work out. Instance resizing could cause that to go as low as 40% if you try and maintain QoS/SLAs, which would destroy the profitability of the public cloud itself. This is also more of a “pets” approach than a “cattle” approach.
For example, imagine you have a piece of hardware 4 cores (4c) and 4GB RAM (4g) that hosts 4 VMs, each of which get 1c/1g a piece (I’m simplifying here so bear with me). Now, each VM is roughly guaranteed one core each. This is an oversubscription ratio of 1:1 (AKA “no oversubscription”). If each customer suddenly resized these VMs to 4c/1g, that oversubscription ratio would change to 4:1, meaning that if all were banging away with their CPUs they would still only be getting roughly 25% of what they asked for, or one core. You can’t provide strong performance guarantees if you allow instance resizing. Now, some of this could be addressed by dynamically reallocating workloads via live migration on the backend and building a sophisticated scheduler to allow “re-packing”, but it would get very challenging in the situations where there simply wasn’t enough immediate capacity to service a request. The reality of the situation is that this is more trouble than it’s worth and customers would be better off learning how to dynamically spin up a new VM and scale horizontally. The new model is cattle, not pets.
I wrote up a detailed example of how oversubscription impacts cloud performance in late 2009.
#6 - Add More Datacenters
No comment. Google has a global reach and will use it. Nuff said.
#7 - Offer Virtual Machine Image Import/Export
Here here. Every cloud needs more of this. I’ve long said that even OpenStack Glance should be working more in this direction.
#8 - Do All of the Above But Faster
Google’s development engine is as fast as Amazon’s and in fact, you could argue that Google pioneered the agile webscale development model. This really comes down to a question of semantics. If you say that public cloud starts with infrastructure and then expands, then Google is chasing Amazon. If you say that public cloud starts with application services like Google Mail/Search/Apps, then Amazon is chasing Google, moving towards application level services. The reality is that either entry point is still “cloud” and that Google and Amazon have been inexorably moving towards each other. Google is the only major competitor to Amazon in this regard already. The only possible exception I would make being Microsoft, but they have their own internal problems to resolve before they are a serious contender.
Look at the number of developer centric APIs Google already has (this is a partial screenshot as the complete list is too long to fit):
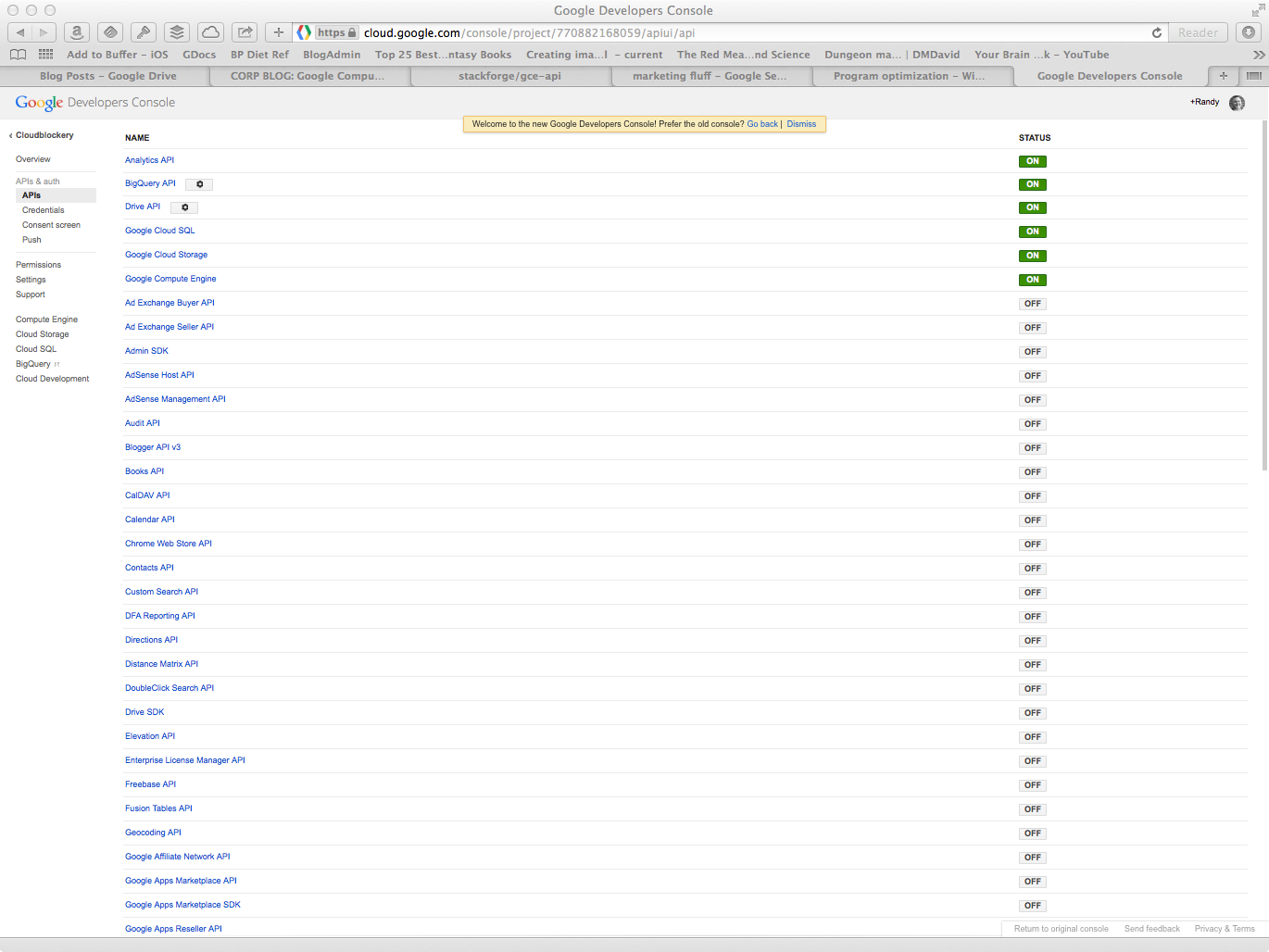
There are over 75 developer APIs across all of Google’s cloud services. Perhaps Amazon should start moving faster? :)
What Was Missed: Google’s Networking Advantage
Interestingly, one of Google’s biggest technical advantages was overlooked. For the past decade Google, Yahoo!, and Microsoft have been buying up dark fiber and deploying it between their datacenters. These folks, particularly Google have massive nation-wide networks capable of Terabit speeds (1000s of Gigabits). These networks interconnect Google datacenters. By some measurements Google is the 2nd or 3rd largest ISP in the USA.
Dark fiber doesn’t grow on trees. It’s incredibly costly to deploy and as what was in the ground has been sold off, it has become progressively more expensive. If you own the dark fiber and light it yourself, you can continue to push more bandwidth across the same strands by using new DWDM gear on either side. If you don’t have dark fiber, you only have access to “lit fiber” that limits how much traffic you can push across.
Google and Microsoft have massive structural advantages in their dark fiber networks and can not only have massive bandwidth between datacenters, but also have it at a very low cost. And Amazon cannot “come from behind” to make up the difference as supplies of dark fiber are now severely limited until the next wave of fiber buildouts and no one has any idea when that will happen.
What can Google do with this? Imagine the ability to have all Google Cloud Storage geo-replicated for free bandwidth costs. With so much bandwidth, moving huge VM images (100+ GB) across the network no longer sounds crazy. What about having your “regions” be as big as the entire eastern or western seaboards? All of this is possible if you have a big, fast, cheap WAN, which Google has and Amazon will never be able to achieve.
It’s Going to be a Two Way Horse Race
Exciting times in cloud land. Amazon Web Services finally has a credible competitor in Google’s Cloud Platform. I’m glad that others are beginning to see the light and I am still hopeful that Microsoft comes from behind and shows up to the party. In the meantime, watching Amazon and Google compete should provide plenty of entertainment and collectively we can all help the cloud revolution happen faster.