The 6 Requirements of Enterprise-grade OpenStack, Part 1
Introduction
OpenStack is an amazing foundation for building an enterprise-grade private cloud. The great OpenStack promise is to be the cloud operating system kernel of a new generation. Unfortunately, OpenStack is not a complete cloud operating system, and while it might become one over time, it’s probably best to look at OpenStack as a kernel, not an OS. [1]
In order to become widely adopted by the enterprise, OpenStack must ultimately be delivered via robust, enterprise-grade products that close the gap on the key areas where OpenStack has challenges. These products are delivered today by businesses that can provide support, ease-of-installation, tools for day-to-day management, and all of the other pieces necessary for achieving acceptance. Without these vendors who have a stake in enterprise adoption, OpenStack can never be widely adopted. OpenStack isn’t MySQL. It’s the Linux kernel, and like the Linux kernel, you need a complete operating system to create success.
So what’s required? There are 6 key elements:
-
99.999% Uptime APIs & Scalable Control Plane
-
Robust Management & Security Models
-
Open Architecture
-
Hybrid Cloud Interoperability
-
Scalable & Elastic Architecture
-
Global Support & Services
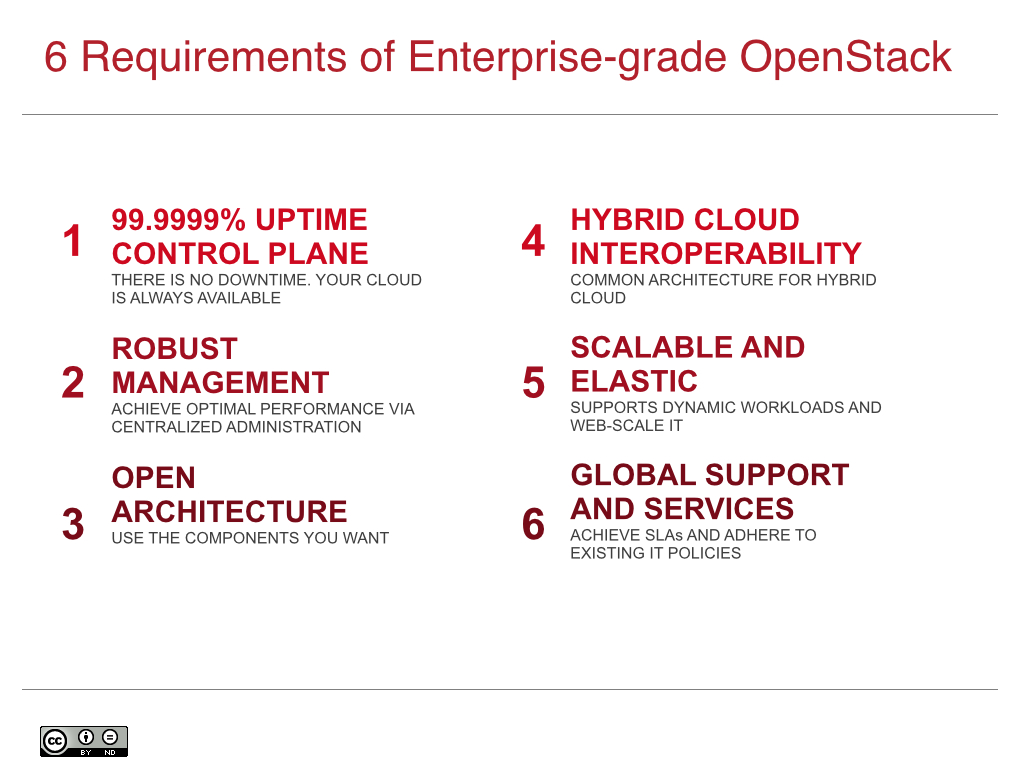
If your business requires an enterprise-ready OpenStack solution, read on to learn more about what a true enterprise-grade OpenStack-powered private cloud can - and should - offer. Over the next two weeks, I’m going to do a multi-part blog series entitled “6 Requirements of Enterprise-grade OpenStack” - where I will detail these six requirements.
To get started, lets look at OpenStack’s place in the enterprise.
OpenStack in the Enterprise Data Center
Agility is the new watchword for cloud and DevOps is seen as the path to realizing agility. OpenStack provides the ideal platform for delivering a new developer experience inside the enterprise, just as Linux provided a new experience for web applications and Internet adoption. If OpenStack was just a “cheaper VMware,” then it would have little or no real value to the enterprise. Instead, OpenStack provides a shining example of how to build a private elastic cloud like major public clouds such as Amazon Web Services (AWS) and Google Cloud Platform (GCP). Just as Hadoop brought Google’s MapReduce (plus it’s reference architecture) to the masses, OpenStack brings the AWS/GCP-style Infrastructure-as-a-Service (IaaS) offering to everyone. This is what makes DevOps inside the enterprise ultimately shine.
Any discussion about DevOps, like so many of the recent buzzwords, can quickly become mired in semantic arguments. However, the one truism we can all agree on is that the traditional barriers between application developers and IT infrastructure operators need to be broken.
Time after time, I hear a similar story from our customers that goes like this: “We went to the infrastructure teams with our long list of requirements for our new application. They told us it would take 18 months and $10M before it would be ready. So we went to Amazon Web Services. We didn’t get our list of infrastructure requirements and we had to change our application model, but we got to market immediately.” That’s because the inherent value of AWS has less to do with cost and more to do with the on-demand, elastic and developer-centric delivery model.
OpenStack levels the playing field inside the enterprise. Private clouds can be built on the public cloud model, enabling developers while simultaneously giving centralized IT control and governance. In essence, it’s the best of both worlds, which is the true value of OpenStack-powered private clouds.
Why Does Agility Matter?
While I think it’s self-evident that agility is the driving light behind cloud computing, it’s worth a quick refresh. The need for businesses to move now has driven ridiculous growth for AWS (see growth below and notice this is a log chart):
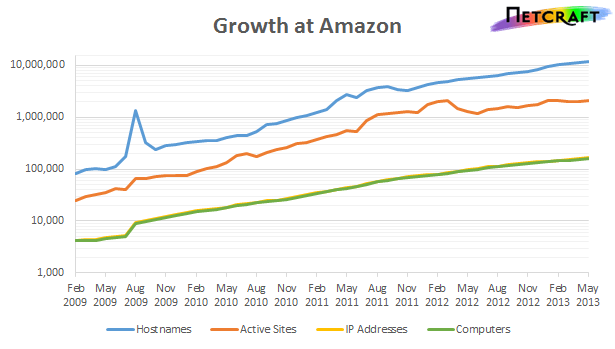 Netcraft AWS Growth Relentless
Netcraft AWS Growth Relentless
This growth is all net new applications, or what Microsoft calls next generation applications. The vast majority of these new applications are focused on creating entirely new business value, typically around mobile, social, web applications, and big data. In fact, this category of application is growing so fast that analysts such as IDC and Gartner have started tracking it [2]:

At its current rate of growth, next generation cloud applications will equal the size of all existing applications by 2018:
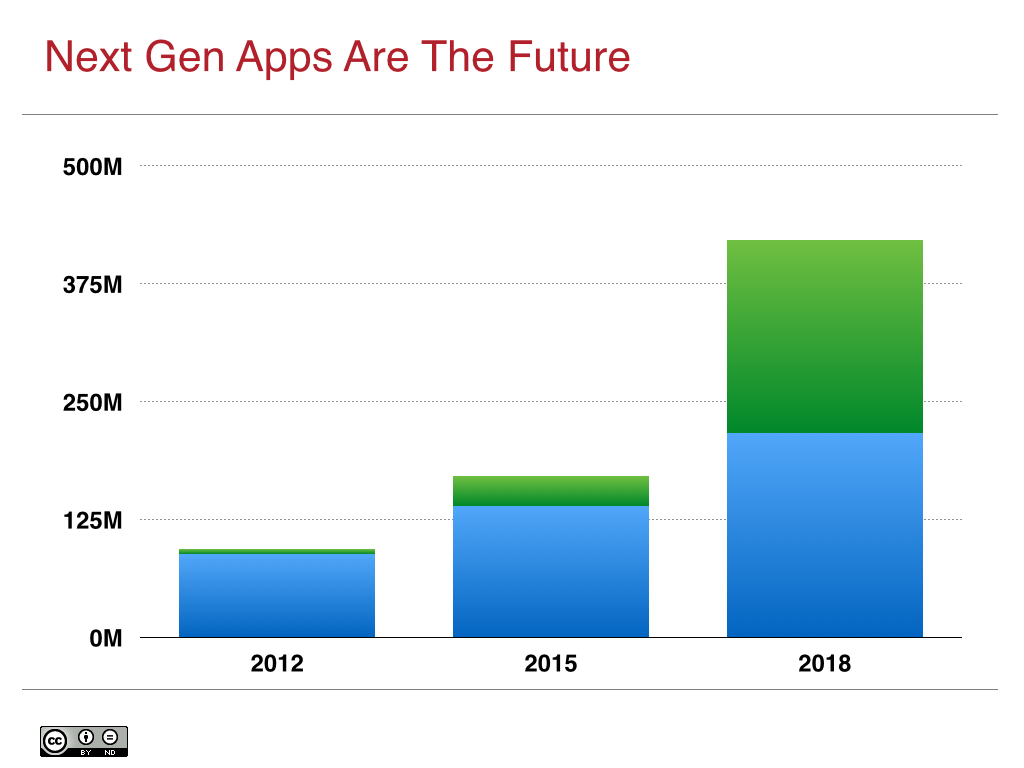
Next generation applications are the source for future competitiveness for most enterprises, which has led them to accelerate their cloud adoption process and rethink their cloud strategy.
Observing this phenomenon is what led Forrester analyst Craig Le Clair to say:
Seventy percent of the companies that were on the Fortune 1000 list a mere 10 years ago have now vanished – unable to adapt to change …
We have now entered an adapt or die moment for enterprises, and OpenStack will be key to agility adaptation and the successful support of DevOps.
Over the next few weeks leading up to the OpenStack Summit I’m going to cover all 6 Requirements of Enterprise-grade OpenStack in detail. Today I am going to handle the first two requirements: high uptime APIs and robust management of your cloud.
Requirement #1 – 99.999% Uptime Control Plane: High Uptime Apps Require a High Uptime API
Continuing our discussion around delivering enterprise-grade OpenStack, let’s discuss how critical API availability and scaling out the cloud control plane are to delivering next gen applications.
Cloud API Uptime & Availability
A critical capability for moving to a new cloud and devops model is the ability of cloud native applications to route around failures in an elastic cloud. These applications know that any given server, disk drive, or network device could fail at any time. They look for these failures and handle them in real-time. That’s how Amazon Web Services (AWS) and Google Cloud Platform (GCP) work and why they can run these services at a low cost structure and with greater flexibility. For an application to adapt in real-time to the normal failures of individual components, the cloud APIs must have higher than normal availability.
Your Cloud Control Plane’s Throughput
API uptime isn’t the only measurement of success. Your cloud’s control plane throughput is also critical. Think of the control plane as the command center of your cloud. It is most of the centralized[3] intelligence and orchestration layer. Your APIs are a subset of the control plane, which for OpenStack also includes all of core OpenStack projects, your day-to-day cloud management software (usually part of a vendor’s Enterprise-grade OpenStack distribution), and all of the ancillary services required such as databases, OpenStack vendor plugins, etc. Your cloud control plane needs to scale-out as your cloud grows bigger. That means that in aggregate, you have more total throughput for API operations (object push/pull, image upload/downloads, metadata updates, etc.).
This is where a proper cloud operating system comes in.
99.999% Uptime APIs and Scale-out Control Plane
In essence, by saying that you can build a four or five 9 app (99.99-99.999%) on a two and a half 9 infrastructure (99.5%), the API that app manages must also have a four or five 9 uptime (99.999%). As most of you know, delivering five 9s of availability is a non-trivial task, as this is only 5.26 minutes of unplanned downtime allowed per year. Typical high availability approaches, such as active/passive or master election systems, can take several minutes to failover, leaving your cloud API endpoints unavailable.
An enterprise-grade cloud operating system can provide guarantees of sub-minute or even sub-second failover and deliver 99.999% or possibly even 99.9999% (that’s six 9s or 31.5 seconds of downtime per year) uptime. This kind of design is achievable at a relatively low price point using classic load balancing style techniques where your control plane and APIs are running active/active/active/active/… to N where N is however many you need as your cloud grows:
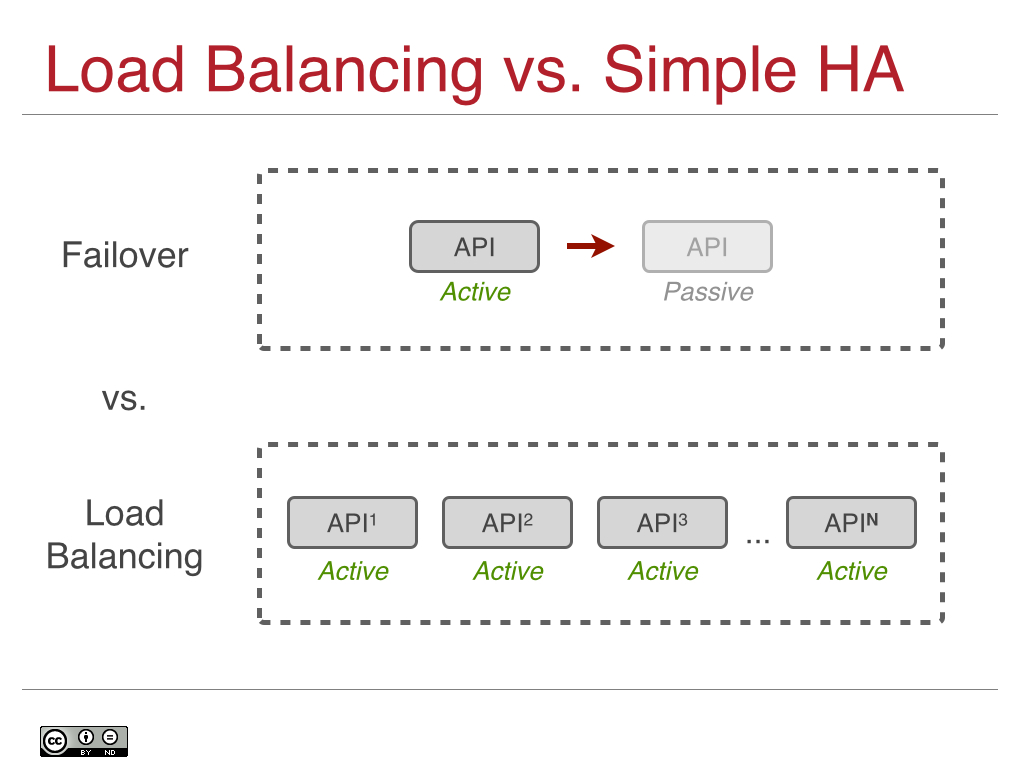
Which brings me to the second part of the equation: you need your control plane to grow as your cloud grows. You don’t want to re-architect your system as it grows, and you don’t want to resort to old school scale up techniques for your API endpoints. When you run active/passive or with a master election system for high availability, only one API endpoint is available at a time. That means that you are fundamentally bottlenecked by the total throughput of a single server, which is unacceptable in today’s scale-out cloud world.
Instead, use a load balancing pattern so you can run multi-master (N-way) active API endpoints, scale your control plane horizontally and simultaneously achieve a very high uptime. This is the best of all worlds, allowing your cloud native applications to route around problems in real-time.
Now let’s talk about day-to-day management of and securing your cloud.
Requirement #2 – Robust Management: Managing and Securing Your Cloud is Not Free
You probably know this already, but building a robust, manageable, and secure infrastructure in the enterprise isn’t easy. The notion that an enterprise-grade private cloud can be delivered in an afternoon and in production that evening doesn’t wash with the realities of the datacenter. Still, time is of the essence and if you want a cloud that doesn’t suck and you want it (relatively) fast, then it will help if the version of OpenStack you choose has been designed with deployment, daily management, and security in mind. Let’s take a deeper look at what that entails.
Robust Management
Installation is only the beginning when it comes to managing OpenStack. A true cloud operating system provides a suite of operator-centric cloud management tools designed to allow the infrastructure team to be successful at service delivery. These management tools provide:
-
Repeatable architectural model, preferably using pods or blocks wired together with a reference network architecture
-
Initial cloud installation & deployment
-
Typical day-to-day cloud operator tools for logging, system metrics, and correlation
-
Cloud operator command line interface (CLI) and API for integration and automation
-
Cloud operator GUI for visualization and analysis
Many attempts to solve the private cloud management challenges stop at installation. Installation is just the beginning of your journey, and how easy it is doesn’t matter if your cloud is then hard to manage on a daily basis. As we all know, running a production system is not easy. In fact, private clouds are significantly more complex than traditional infrastructure approaches in many aspects. To simplify the issue, at scale, the cloud pioneers, such as Google, Amazon, and Facebook have all adopted a pod, cluster, or block based approach to designing, deploying, and managing their cloud. Google has clusters; Facebook has triplets; but it’s all ultimately the same: a Lego brick-like repeatable approach to building your cloud and datacenter.[4] Enterprise-grade OpenStack-powered cloud operating systems will need to provide a similar approach to cloud organization.
Once the cloud is up and running, cloud operators need a variety of tools to maintain the cloud on a regular basis, including event logs and system metrics. Sure, in an elastic cloud events that used to be critical (e.g. server or switch failure) are no longer high priority. However, your cloud can’t be a black box. You need information on how it’s operating on a daily basis so you can troubleshoot specific issues as required and most importantly keep an eye out for recurring issues using correlation tools. An individual server failure might not be a problem, but any kind of common issue that is effective large amounts of resources needs to be sought out and quickly addressed.
What is your cloud doing? Not only do you need to know, but your other tools and groups may need to know as well. Integration to existing systems is critical to broad adoption. Any complete solution will have an API and command line interface (CLI) to allow you integrate and automate. A CLI and API for just OpenStack administrative needs is not enough. What about your physical server plant or management of your blocks or pods? How about being able to retrieve system metrics and logging data on demand from not only OpenStack, but Linux and other non-OpenStack applications? You need a single, unified interface for cloud operations and management. Obviously, if you have this API, a GUI should also be provided for those unique cloud operator tasks that require visualizations such as looking for patterns in system and network metrics.
Security Model
Cloud turns the security model on its head. A complete discussion of this topic is far beyond the scope of this blog, but I do know one thing: enterprises want a private cloud with an understandable security model, particularly for the control plane. As I covered in the previous installment of this series, your cloud control plane’s API uptime and throughput is critical to allowing next generation applications to route around trouble. Similarly, the security of your cloud’s control plane should not be taken for granted.
It can be easy to get caught up in the move towards a decentralized model, but decentralized and scale-out are not the same thing. You can actually mix centralization and scale-out techniques and this is the default model that cloud pioneer Google uses. Keeping your cloud control plane in one place allows you to:
-
Have a single go-to location for troubleshooting
-
Always know where your control plane is located rather than having to guess
-
Apply security policies/zones to your control plane
-
Keep your control plane data (the system of record) completely separated from data plane data
This last item is perhaps most important. You don’t want your OpenStack database to reside on the same storage system as your virtual machines. What if someone breaks into a VM through the hypervisor? Or, conversely, what happens if someone breaks into the control plane via an API?
Best practices in the enterprise have long comprised an approach of zoning (usually with VLANs) of different components into different security areas with differing policies applied. Zoning slows an attacker down, gives you time to detect them, and to respond. Being able to take a similar approach to your private cloud security model is vital to making certain your cloud is secure.
Cloud Management and Security
As I said, your journey begins with the installation of the cloud. After that, you need a set of tools and a security model that allows you to confidently manage your cloud day by day. An Enterprise-grade, OpenStack-powered cloud operating system should deliver as much of these capabilities as possible.
Part 1 Summary
OpenStack is a strong foundation for building a next generation private cloud designed for next generation cloud applications. Unfortunately, it isn’t a complete cloud operating system and you will need a partner to provide you with that solution. This series is covering The 6 Requirements of Enterprise-grade OpenStack and in today’s blog posting I covered the need for a high uptime, scale-out control plane and robust, secure management tools.
In the next installment I will cover building around an open architecture and reducing vendor lock-in. That will be followed by the closing posting covering the need for filling in the gaps around scalability and performance and choosing a partner who can provide global services & support.
Second Installment:
Final Installment:
UPDATE: Added references for the growth of new net new apps.
[1] In fact, even the OpenStack Foundation is about to refresh it’s messaging to help clarify this.
[2] The original source for this is EMC, both at this blog posting and via a private presentation by Joe Tucci, CEO of EMC, at a Research Board event.
[3] Yes, centralized. Something can be centralized and still scale-out. Centralization is necessary for proper security policies and zones to be enforced.
[4] Google’s cluster architecture has quite a bit of detail here.