Hyper-Converged Confusion
I have had my doubts about converged and hyper-converged infrastructure since the Vblock launched, but I eventually came around to understanding why enterprises love the VCE Vblock. I am now starting to think of converged infrastructure (CI) as really “enterprise computing 2.0”. CI dramatically reduces operational costs and allows for the creation of relatively homologous environments for “platform 2” applications. Hyper-converged infrastructure (HCI) seeks to take CI to the next most obvious point: extreme homogeneity and drastic reduction in labor costs.
I can see why so many come to what seems like a foregone conclusion: let’s just make CI even easier! Unfortunately, I don’t think people have thought through all of the ramifications of HCI in enterprises. Hyper-converged is really an approach designed for small and medium businesses, not larger enterprises operating at scale. The primary use cases in larger environments is for niche applications with less stringent scalability and security requirements: VDI, remote office / branch office servers, etc.
There are three major challenges with HCI in larger scale enterprise production environments that I will cover today:
- Security
- Independent scaling of resources
- Scaling the control plane requires scaling the data plane
I think this perspective will be controversial, even inside of EMC, so hopefully I can drive a good conversation about it.
Let’s take a look.
##Background and Definitions
Hyper-converged infrastructure is a class of infrastructure that arose on the heels of “converged infrastructure” of which the VCE Vblock is the canonical example. There isn’t a canonical version of hyper-converged, but leaders in the space include Nutanix, Simplivity, Pivot3, Maxta, VMware’s EVO:RACK / EVO:RAIL, and EMC’s own VSPEXblue are up and comers. Hyper-converged in OpenStack land is represented quite well by Piston Cloud, who doubled down on this architecture early, which attracted investment from Cisco Systems, one of the original investors in VCE and co-creators of the converged infrastructure marketplace.
There are some definitions out there that we can leverage to set initial context.
Converged infrastructure (CI):
Converged infrastructure (CI) is an approach to data center management that relies on a specific vendor and the vendor’s partners to provide pre-configured bundles of hardware and software in a single chassis.
Hyper-converged infrastructure (HCI):
Hyper-convergence (hyperconvergence) is a type of infrastructure system with a software-centric architecture that tightly integrates compute, storage, networking and virtualization resources and other technologies from scratch in a commodity hardware box supported by a single vendor.
These definitions are somewhat helpful, but they obscure what I see as the fundamental difference between CI and HCI. While it’s true that HCI is inherently a software-centric model, there is nothing that says that a software-centric model can’t be applied to CI. In fact, if you look at Cloudscaling’s product, Open Cloud System, it was largely a software-centric model applied to converged infrastructure. You could swap out any hardware you wanted as the “pre-configured” bundles were basically software abstractions that could be applied to any certified hardware we supported.
When we look at HCI, the reason that it’s software-centric is that if you go to the extreme where you provide a highly homogeneous environment, you can’t have specialized nodes in the system that are focused on a particular workload like storage or compute. Instead, you run storage and compute everywhere. But, of course, HCI still isn’t 100% software-centric as it still relies on “appliances” for networking in the form of a switch fabric.
And, of course, CI systems have significant software-centric components, for example VMware’s NSX a software-defined networking solution, runs on Vblocks.
What I am saying here is that the existing definitions are wrong. The software-centric architecture that supposedly sets HCI apart is the outcome of running a flat, homogeneous system, not the other way around. Also, the software-centric architecture can be applied to CI, so it’s not really what is unique about hyper-converged.
What is unique to hyper-converged is that a choice was made to drive more cost and labor efficiencies by trying to standardize and drive conformity in the system through extreme homogeneity.
This required a software-centric architecture, but also has the side effect of creating a major flaw in the design: the collapsing of the control plane and data plane into one. If all nodes are homogeneous, where does your control software go? It goes everywhere on every node, and that is a major challenge for the security conscious.
The key to understanding the flaws in HCI for larger production deployments is the very fact that the control plane and data plane have been collapsed into a single system.
Let’s dig into those three areas I mentioned as being flawed: security, resource scaling, and control plane scaling.
##Security
There is now almost 20 years of security best practices characterized by “defense-in-depth,” a tried and true approach to stopping or, at least, slowing attackers. A hyper-converged infrastructure, in collapsing the data plane and control plane, makes it impossible to create partitions between areas of a system such that a variety of security measures can be deployed. In effect, it means that you can’t use defense-in-depth principles. A penetration anywhere results in the system being completely “owned” or if you prefer, pwned.
This is why, for example, the PCI specification requires you to provide “network segmentation” between your database and the rest of the system. This is very difficult, or impossible, to achieve in a hyper-converged system. Sure, you can do some fancy tricks with virtual switches, but to a certain degree it doesn’t matter, because at the storage layer, your production database is stored on the same storage as your VMs. If an attacker breaks in, they will have access to everything anyway, so network segmentation is irrelevant.
What the value in having network isolation if all data is stored on all machines for all purposes and workloads? None.
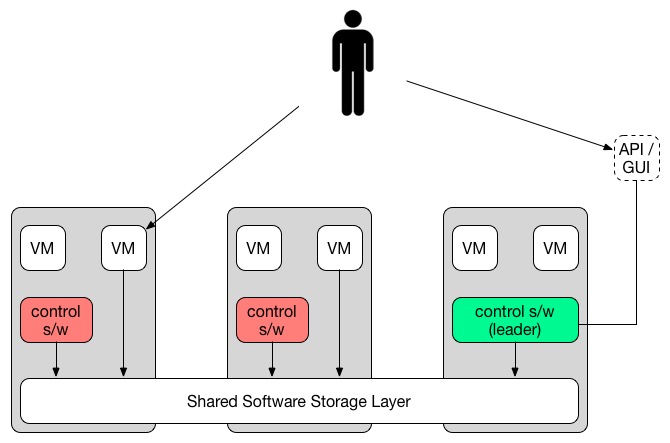
Here’s the exercise: insert a firewall between all of the places the control software can run and all of the “data plane” where the virtualized resources are. Protect the shared storage layer in such a way that an attacker who breaches the APIs can’t access VM data or such that if the same attacker breaches a hypervisor he can’t read the primary database of the control software.
It’s not easy, and any “software-centric” approach to attempting to do so would have inherent limitations given it’s a software-only approach.
As you can see, this kind of approach isn’t going to be acceptable in most enterprise environments. In fact, I’m pretty sure you can’t get through a compliance audit with this kind of system so it’s unlikely they will ever support production, web-facing applications or really any enterprise app with any kind of real security requirements. Most usage in the enterprise will be VDI, dev, test, QA, and other niche applications.
##Independent Resource Scaling
One downside of a Vblock has been running out of capacity, such as disk IO, before completely exhausting another resource such as memory or CPU. A reasonable criticism, however, hyper-converged just amplifies this problem. Rather than running out of capacity in a single block or rack, you can run out of a resource across the entire cluster. If you have 10 nodes that provide X disk IOPS and Y RAM, you can have the situation where you are using all of X, but have half of Y, meaning that your per VM cost is actually doubled because you overspent on the nodes.

As an aside, this is why VCE recently announced their Technology Extensions to support independent scaling of resources. This kind of approach to mitigating the above weakness in a Vblock simply can’t exist in HCI because of its extreme homogeneity and collapsed control plane.
The most successful and largest hyperscale/webscale clouds all, without exception, scale cloud resources such as network, storage, and compute independently of each other. Heck, the default AWS instance doesn’t even have local disk (ephemeral storage) any more!
In fact, while it’s true that hyperscale players are relatively homogeneous (what I call “homologous” or “mostly homogeneous”), they are not nearly as homogeneous as a typical hyper-converged infrastructure system. The reason is that while relative homogeneity provides certain economies of scale, extreme homogeneity actually reduces your economies of scale by creating large amounts of unused resources.
You have to fit your workloads to hardware that has been purpose-designed for that particular workload. When you don’t, you inherently hurt your capex efficiencies, more than you make up for it with opex/labor efficiencies.
Again, this isn’t really an acceptable architecture for a larger cloud or a production system, but it’s a great architecture for smaller businesses and niche applications where you have a known, relatively fixed workload (e.g. VDI) or where you don’t care if the workload is inefficient (e.g. dev/test/QA).
##Scaling the Control Plane Means Scaling UP the Data Plane
In a hyper-converged system the “control plane”, or the software, APIs, and control systems that manage the system, are “distributed”. In practice, this means that the control plane software and data is mixed with the VMs and VM data storage. It also usually uses the same network. Yes, this is a security problem, but it also uncovers another issue, which is that there isn’t a specific entry point. You have 10 nodes, which ones are running the control plane at any given time? It can’t be all of them, because then what do you when it’s 100 nodes? Or 1,000?
This is frequently resolved by having the control software run on a single node at a time. That node is selected using a master (“leader”) election system. The problem with a master election system is that there is only one master at a time. That means that on the same box that is hosting VMs and storage your control plane system and APIs are running. If you run out of “oomph” because you don’t have enough resources, there is only one solution: upgrade the node you are running on.
Whoops! In a hyper-converged system homogeneity forces us into an awkward situation. If you upgrade one, you really need to upgrade all, since you have no way of knowing on which system your control software(s) will be running at any given time. Again, this creates major cost inefficiencies and isn’t acceptable in an enterprise cloud that supports production applications.
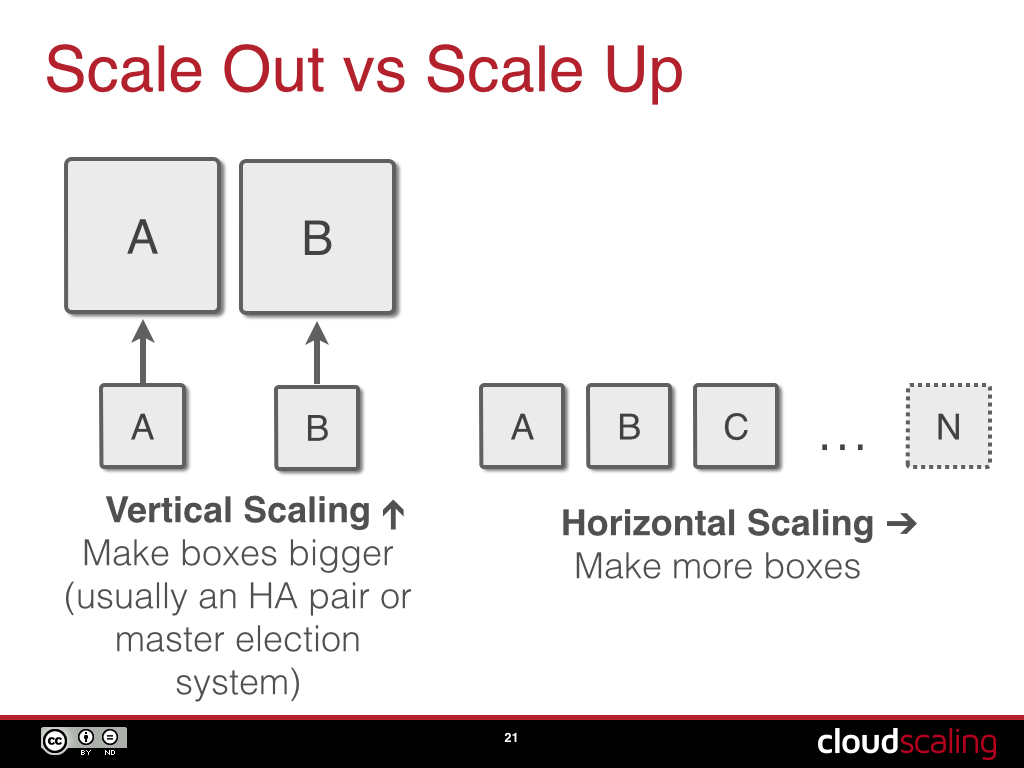
Not only that, it means that you are running a scale-up control plane rather than a scale-out one. Scale-out systems get more capacity by adding more nodes horizontally, but if you only run one instance of the control plane software at a time, you can’t get N-way horizontal scalability.
##So, Why Run Hyper-converged Infrastructure?
As far as I am concerned the primary value proposition of a hyper-converged system is it’s simplicity, which results in a significant reduction in the cost of labor. A single good IT person can manage a hyper-converged cluster part time. So, of course, this is why it’s ideal for an SMB or SME environment. Or perhaps in niche applications within the enterprise around VDI and development support.
Unfortunately, this is also why it’s really a terrible option for any kind of “real cloud” in a larger enterprise.
There are some other minor quibbles I have with hyper-converged, like the general lack of anything resembling a failure domain and that the control plane isn’t designed for horizontal scalability, but I think this article will help your understanding of the most egregious issues.
Frankly, hyper-converged infrastructure is more likely to have a place in a wiring closet rather than the datacenter itself.
I think that your basic decision making process when buying converged infrastructure should be:
- Will I run production applications on this system -> CI
- Will I need to pass security and compliance audits -> CI
- Do I need to run more than a handful of racks of capacity -> CI
- Are the workloads relatively fixed and known ahead of time -> HCI
- Is this in a remote branch office? -> HCI
- Do I care more about the cost of labor than hardware? -> HCI
As always, use the right tool for the job. Hyper-converged infrastructure is no panacea, but it does have a place.